The next 5 biggest challenges in neural machine translation

The last few years have witnessed the rise of Neural Machine Translation (NMT), which has taken over the entire translation services industry. And this is just the beginning of a new era for the translation business. NMT has displaced rule-based translation systems, statistical machine translation (SMT) and all previous efforts of automatic translations. In some languages, NMT steadily approaches near-human translation quality. Along with the great results, however, challenges have emerged along the way. In this article we will discuss five of the most difficult challenges facing NMT today.
1. Out of domain
Let’s start by illustrating the concept behind this challenge with a short example. If we take the word “second” for instance, it can be a measurement of time or also denote the placement of something or someone after the “first.” These different domains equal different meanings, and should end up with different translations.
Why is this such an important topic? The main reason is the development of targeted domain-specific systems instead of broad or cross-domain systems, which result in a lower translation quality. A popular approach is to train a general domain system, followed by training on in-domain for a few epochs, in other words a bit of customization into the specific domains.
In the field, it is very common to find large amounts of training data, opus, paracrawl, TED Talks, etc., available for a very broad domain. This makes a domain adaptation exercise crucial to build a successful system using those public data sets. Here at Acclaro, we have trained engines targeted for a very specific domain with generic data sets, such as legal. Not only will the system encounter out-of-domain words, but it also will find a lot of new words not included in training. As a note, this was an exercise for low-resource language pairs and the entry point for building a targeted neural machine translation engine.
To illustrate the problem more in depth, let’s look at the following table from Phillipp Koehn’s book, Neural Machine Translation.
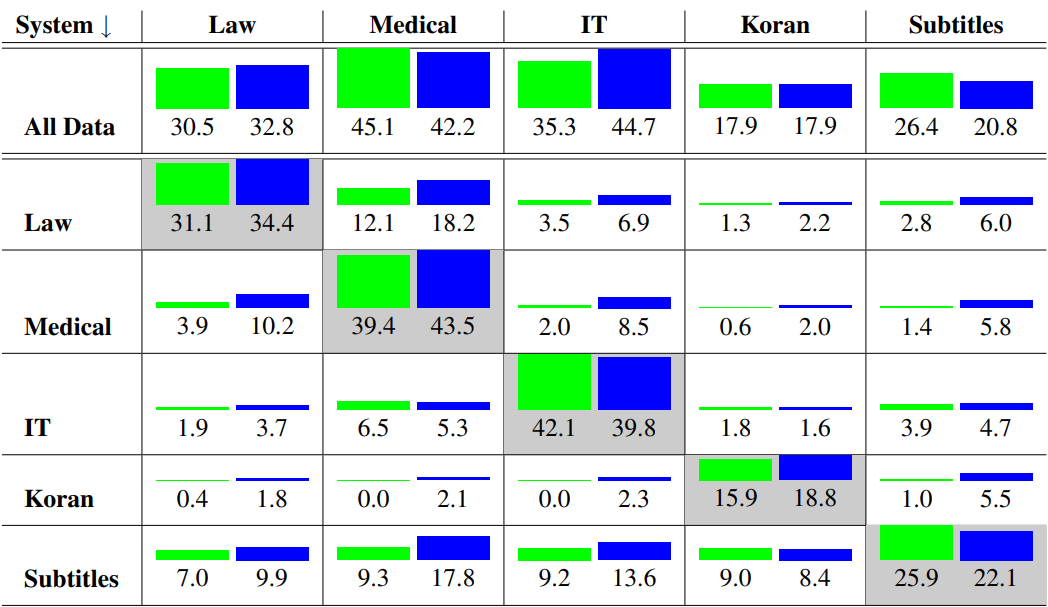
Image caption: Quality of Systems (BLEU) when trained on one domain (rows) and tested on another domain (columns), NMT as green bars and SMT as blue.
The experiment reaffirms our problem and shows in a very concise way how important it is to address the domain adaptation before training the engine, making sure that the most important part is consistent data in the desired domain.
2. Amount of training data
Machine translation quality relies heavily on the amount of training data. For SMT systems, the correlation between quality of the system and BLEU scores was almost direct, but in NMT the relationship, like the Facebook status, is complicated. When NMT finds more data, it is more certain to generalize and perform better within the larger context.
To be more quantity-specific, the numbers can vary depending on the languages. A NMT system needs at least 20 or more million words, and really outperforms any other system when the amount of words is higher than 30 to 35 million words.
To make our case stronger and offer a great example, let’s borrow the following chart from Koehn.
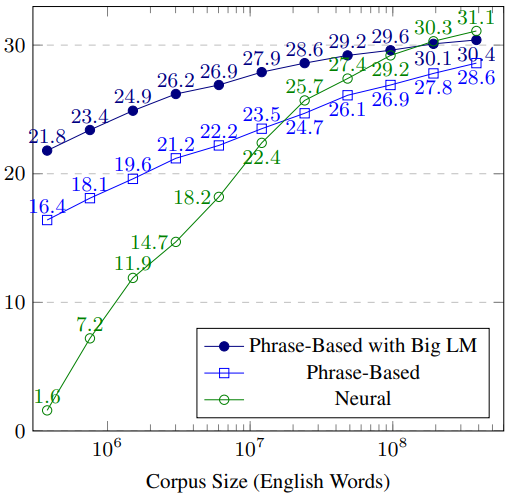
The chart illustrates how the NMT system depends heavily on data. It needs a huge amount of training data, which is not always so easy to find, especially when dealing with rare domains or low-resource languages.
3. Long sentences
A long-known flaw of NMT models, and especially of the early encoder-decoder architectures, was the incapacity to translate long sentences properly. Fortunately, sometime in 2018, the attention model remedied this problem somewhat, although not entirely. In our many experiments with a migration to the attention models, we came to the consensus of cutting long sentences with a threshold of 50 to 60 words as maximum to obtain the best possible results in every translation request. The overall results showed an immense decrease in BLEU scores when surpassing the 54 tokens in a particular translation request.
As a side note, it is important to mention that SMT on sentences of 60 or more words does not show the same weakness as NMT. However, the same problem appears in SMT after 80 or more words (aka very long sentences).
4. Beam search
The task of translation has been tackled over the years with different search techniques that explore a subset of the space of possible translation. A common parameter in those searches is the beam size argument that limits the number of translation tokens maintained per input word. While in SMT there is typically a clear relationship between this parameter and the model’s overall quality score — the larger the beam search, the greater the expected score should be. In NMT there are two factors to consider, for big beam numbers the NMT BLEU scores from top performance to mediocre or even really bad translations.
When setting up the beam score, Acclaro’s NMT group discovered that a beam number between five and eight proved to be the best possible alternative, with a beam number over 10 always something we don’t recommend, as it negatively impacts model output and model performance. Why? In short, because the number of words per second that the model can translate is determined by the logical pattern that the model considers when using a longer beam search. The higher the word count, the more the model needs to consider each partial translation and subsequent word predictions.
That’s one of the reasons why our recommendation is to never overestimate your beam search. Depending on performance, keep your number between five and eight for an optimal score and words-per-second rate.
5. Word alignment
In almost every translation request, there is a need for word alignment to correspond between the source and target text. The reasons for this can include tags, formatting, ICU or a long list of features that we encounter daily. Fortunately, the key aspect of the attention mechanism (included in our NMT engines since 2018) is the attention table, which includes every probability for words in alignment between input and output words.
But here lies the challenge surrounding word alignment for NMT: the role that the attention mechanism plays for the correspondence between input and output words is not the same as in SMT. With NMT the attention technique has a broader role, paying attention to context. For instance, when translating a noun, the subject in a sentence, attention may also be paid to the verb and any other words related to or describing the subject. Context can help clarify the meaning. That said, word alignment itself is not the most reliable way to determine any given word’s meaning — and it certainly cannot be the only way to determine meaning.
The attention model, for the above reasons, may choose alignments that do not correspond with our intuition or alignment points. We strongly suggest that translation tasks that involve alignment features include a guided alignment training where supervised word alignments (such as the ones produced by fast-align, which more closely corresponds to intuition) are provided to train the model.
Crossing the final NMT barriers
Notwithstanding the widespread success of NMT, there are still a few barriers that NMT has yet to cross. Of these five biggest challenges we’ve covered, out of domain and the amount of training data (not enough) take a huge portion of performance out of the table for any system. As we seek to address these challenges, Acclaro’s NMT group is always happy to collaborate with NMT practitioners and researchers who have a similar focus. And, last but not least, we encourage our clients to consider those two factors as the most prominent ones whenever they use machine translation: How much data is enough data? And is the data in the domain I want? Talk to us today about how we put this data to work when building a successful localization program.
Insights for global growth




