Managing translation with segmentation rules

Translation memory (TM) is essential for running successful and economical localization projects over time, and segmentation rules are crucial to that success. If you’re an enterprise that is considering releasing its products in a new market, read on to discover how it affects your translation efficiency and savings.
What are segmentation rules?
When we refer to segmentation rules, we are generally referring to a segmentation rules exchange (SRX) file saved to the given translation tool. The SRX file governs how a body of text is broken down into small pieces in a computer-assisted translation (CAT) tool. They will apply to the files uploaded into the CAT tool or the data stored in a repository connected to your translation management system (TMS).
Let’s consider a few scenarios of how segmentation rules might apply to an organization.
1. String-based in software development: several sentences, phrases, lists, etc. and are bundled together and identified by a key. Although quite long, the following is recognized by the TMS as a single segment.

2. Cell-based in gaming: multiple sentences contained in a single spreadsheet cell (such as A2 and A3).
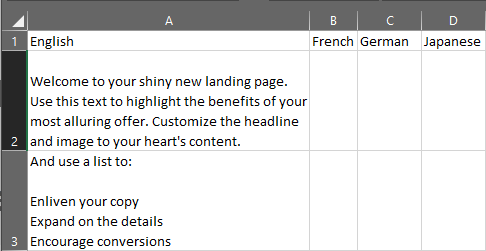
3. Sentence-based in documentation: broken down by individual headings, subheadings, sentences, call-outs, bullet points, etc. The most precise approach, because of the smaller segment size.
Mechanics of TMs
You may recall, a TM is a simple but powerful bilingual database. (See Human Translators & Translation Memory: The Perfect Match for reference.)
The TM remembers the string-, cell-, or sentence-based segment and its corresponding target translation in pairs.
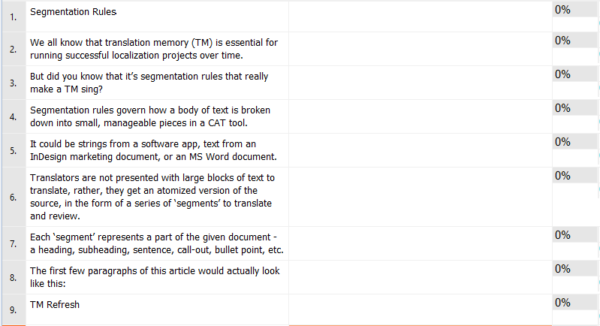
When we apply machine translation to the opening paragraphs of this article using sentence-based rules, it will look like the following.
Segment 1 will pair the English phrase “Segmentation Rules” in English together with it’s Japanese translation “セグメンテーションルール” in the TM—and so on for each successive segment.

And why does this matter?
1. Agile development significantly impacts localization efforts
The choice of which localization tool is used to produce multilingual content is often made by developers working in an agile environment. Strings are ubiquitous in software development, and there are many compelling reasons why developers would want to use string-friendly tools in their process.
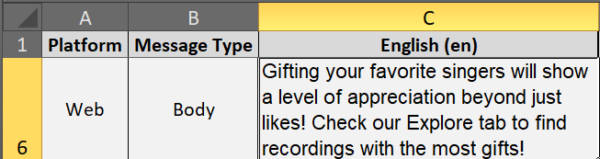
The problem is, strings can contain a massive amount of content. In the string-based screenshot above, there are approximately 200 words. (We have seen some strings with more than 1,000 words!)
That complicates maintaining usable TM leverage. All it would take is a few extra spaces, a line break, etc., and your fuzzy match score will fall significantly.
2. Flexibility
But it also matters because you can change the rules to suit your needs. You can set up multiple TMs, each with its own custom set of segmentation rules. The key (no pun intended) is to consistently use the same rules across the range of your content.
So, if you need to optimize the handling of content in spreadsheets, no problem!
Best practice: sentence-based parsing
This is why we recommend using sentence-based parsing, even for your software development.
Let’s say this blog post is 1,000 words long, and we decide to translate it into French. Then, some months later, we change one sentence.
If sentence-based rules were used, it is much easier to identify the delta in each one. The TM will analyze every sentence, one-by-one. We would expect to get predominantly 100% matches for all sentences, except for the one that was changed.
Set it and forget it
To be clear, TM leverage is paramount for recycling translated content and reducing cost. The segmentation rules are usually a “set it and forget it” type of configuration. Unless you have specific needs, the default segmentation rules in the CAT or TMS you use should suffice.
If you’re about to localize into several target languages, our localization engineering team can help you with a translation readiness step. Contact us today and put our decades of knowledge and experience to work for you!



